New progress in the research of human brain visual information encoding and decoding
December 19, 2018 Source: Chinese Academy of Sciences
Window._bd_share_config={ "common":{ "bdSnsKey":{ },"bdText":"","bdMini":"2","bdMiniList":false,"bdPic":"","bdStyle":" 0","bdSize":"16"},"share":{ }};with(document)0[(getElementsByTagName('head')[0]||body).appendChild(createElement('script')) .src='http://bdimg.share.baidu.com/static/api/js/share.js?v=89860593.js?cdnversion='+~(-new Date()/36e5)];The continuous development of modern cognitive neuroscience and functional magnetic resonance imaging (fMRI) has made it possible to interpret brain visual cortical signals using scientific methods. Studying human brain visual information decoding model can not only deepen people's research on human brain visual information processing mechanism, but also effectively promote the development of a new generation of Brain-Computer Interface (BCI) technology.
Although the existing visual information decoding model performs well in the classification and recognition tasks of brain signals, it is still very difficult to accurately reconstruct the visual stimulus content through the brain visual cortex signal. Factors that hinder people from effectively decoding visual information include fMRI data dimensions, sample size, noise, and unscientific decoding models. The traditional multi-Voxel Pattern Analysis (MVPA)-based visual information decoding method directly establishes the mapping relationship between the high-dimensional fMRI voxel space and the visual image pixel space. This decoding method is easy to cause redundancy. Or over-fitting of noise voxels. In addition, the existing methods of decoding visual information are mostly based on linear transformation of visual images, without the information processing mechanism of the human brain vision system, the decoding effect is poor and the biological basis is lacking.
He Huiguang, a researcher at the Institute of Automation, Chinese Academy of Sciences, has been working on brain decoding for more complex stimuli (such as faces, natural images, and even dynamic visual stimuli) in recent years. Following last year's work on "Reconstructing Images with fMRI Signals" was reviewed by MIT Technology Review. After the headline report, based on the accumulation of past work, a brain visual information decoding model based on Bayesian deep learning (see Figure 1) is proposed. For the problem of coding and decoding of visual neural information based on fMRI data, a unified multi-view depth is proposed. The Deep Generative Multi-view Model (DGMM) (see Figure 2) provides an effective solution for visual image reconstruction based on brain signals. Related research results "Reconstructing Perceived Images from Human Brain Activities with Bayesian Deep Multi-view Learning" have recently been published online in the field of neural networks and machine learning IEEE Transactions on Neural Networks and Learning Systems (TNNLS) for brain-computer interface Further research has laid a solid foundation.
The study establishes the relationship between visual image and brain response in a scientific and rational way, transforming the visual image reconstruction problem into the Bayesian inference problem of missing views in the multi-view implicit variable model. Inspired by the human brain visual information processing mechanism (hierarchical, Bottom-up, Top-down), the team used deep neural networks to extract visual features and concepts layer by layer from visual images, which improved the expressiveness and interpretability of the model. Inspired by the voxel receptive field of visual regions and the sparse expression criteria of visual information, the team used sparse Bayesian learning to automatically screen out voxels that contribute to the decoding of visual information from a large number of voxels, and improve the model. Stability and generalization capabilities. The depth-generated multi-view model makes full use of the correlation information between fMRI voxels, effectively suppresses the interference of voxel noise, and enhances the robustness of the algorithm. Thanks to the advantages of the Bayesian approach, the deep-generation multiview model can easily and flexibly fuse prior knowledge to improve predictive performance. A large number of experimental results verify the superiority of the depth-generated multiview model. The new algorithm provides a well-established general framework for brain signal decoding problems, and is highly scalable, allowing it to be extended from different angles to suit different tasks. This project not only provides a powerful tool for exploring the visual information processing mechanism of the brain, but also provides technical support for the development of brain-computer interface, which will promote the development of brain-like intelligence.
The first author of the paper is the doctoral student Du Changde. The work was also funded by the National Natural Science Foundation of China, the Chinese Academy of Sciences Pilot Project, and the Outstanding Membership Program of the Chinese Academy of Sciences Youth Promotion Association.
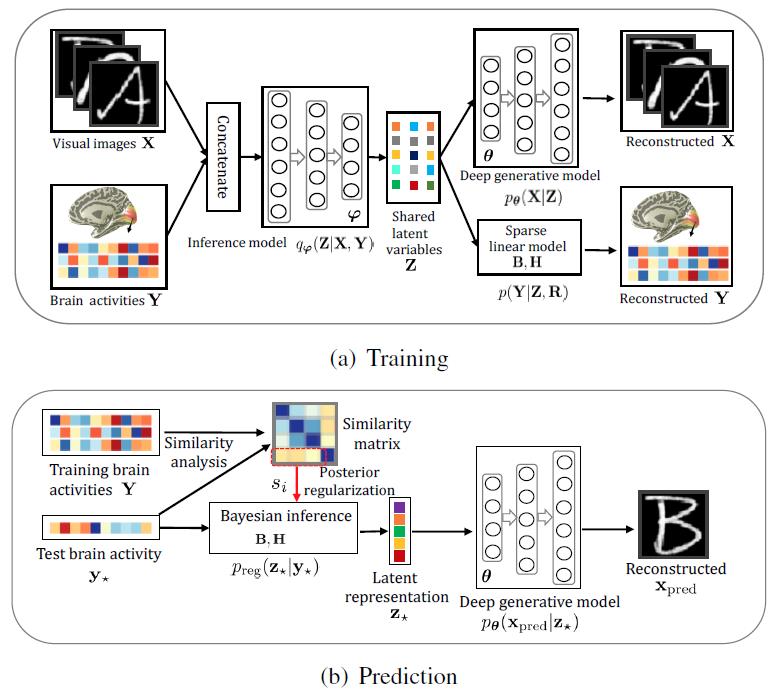
Figure 1: Visual information coding and decoding framework based on Bayesian depth multi-view learning
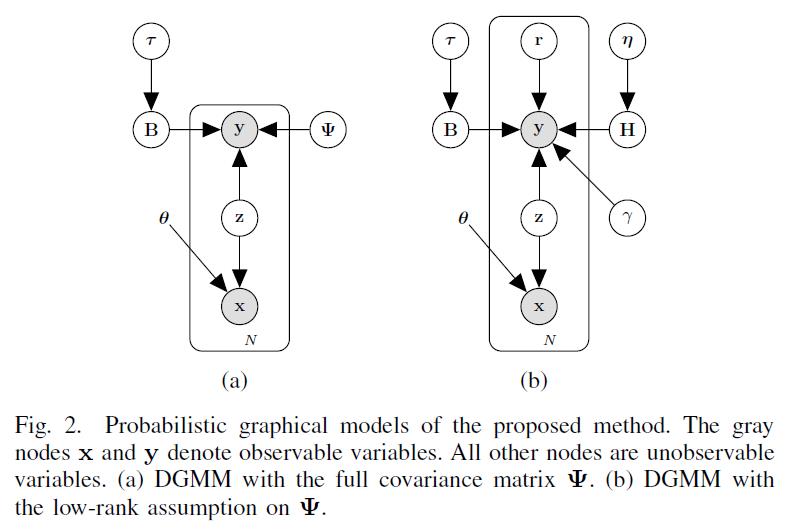
Figure 2: Deep-Generation Multiview Model (DGMM)
Tetanus Toxoid Vaccine,Toxoid Vaccine,Hep B Immune Globulin,Immunoglobulin Injections
FOSHAN PHARMA CO., LTD. , https://www.fs-pharma.com